Multimodal Foundation Models: Architecture & System Design
Comprehensive analysis of multimodal foundation model architectures, training methodologies, and system engineering challenges for vision-language AI systems
Practical Exercises
- Architecture analysis of CLIP, DALL-E, and GPT-4V computational graphs
- Memory profiling of cross-modal attention operations
- Design inference serving system for multimodal chatbot
- Optimize vision encoder throughput for real-time applications
Tools Required
Real-World Applications
- Multimodal chatbots and virtual assistants
- Content generation and creative AI tools
- Visual question answering systems
- Autonomous vehicle perception pipelines
Next Modules
Part of Learning Tracks
Multimodal Foundation Models: Architecture & System Design
Editor's Note: Multimodal foundation models represent one of the most significant architectural innovations in AI, combining vision, language, and other modalities in unified systems. Understanding their design is crucial for AI system architects working with next-generation applications.
🧠 Conceptual Foundation
What Are Multimodal Foundation Models?
Multimodal foundation models are large "base" models pretrained on multiple data modalities—typically some mix of text, images, audio/speech, and video—so they can understand, align, and generate across those modalities with minimal task-specific tuning. Think of them as the successor to text-only LLMs: same pretrain-then-adapt recipe, but with richer inputs/outputs.
Examples include: "explain this chart," "transcribe and summarize this meeting," "write code from this UI mock," "describe this MRI slice," "answer questions about this video clip."
Core Ideas (Why They Matter)
- Shared Representation: Different modalities are projected into a common latent space so the model can "reason" across them (e.g., connect a plot region to the phrase "confidence interval").
- Reusable Capability: One pretraining run supports many downstream tasks: captioning, VQA, OCR, speech recognition/translation, grounding, retrieval, text-to-image, image editing, video Q&A, etc.
- Tool-Like Behavior: With instruction tuning, they follow prompts like LLMs but grounded in pixels/waveforms, reducing hallucinations when the answer is in the input.
- Emergent Capabilities: Demonstrates abilities not explicitly trained for
- Scale-Dependent Performance: Capabilities emerge at specific parameter counts
Historical Evolution & Motivation
The development of multimodal models addresses fundamental limitations of unimodal approaches:
- Information Completeness: Real-world understanding requires multiple sensory inputs
- Efficiency: Unified models avoid redundant representation learning
- Transfer Learning: Cross-modal knowledge improves performance on both modalities
- Human-Like Intelligence: Natural intelligence is inherently multimodal
🏗️ Common Architectures (Three Families)
1. Dual-Encoder, Contrastive (Retrieval-First)
Pattern: Separate encoders per modality map inputs into the same embedding space; trained with contrastive loss (e.g., CLIP).
Text Input → Text Encoder → Text Embedding
↓
Contrastive Loss
↑
Image Input → Vision Encoder → Vision EmbeddingTechnical Details:
- Vision Encoder: Vision Transformer (ViT) or ResNet backbone
- Text Encoder: Transformer-based language model
- Embedding Dimension: Typically 512-1024D for alignment
- Training Objective: InfoNCE contrastive loss
Strengths: Fast retrieval, scalable indexing, reusable embeddings Limitations: Weaker at generative "describe/answer step-by-step" tasks without adding a decoder
System Implications:
- Memory pattern enables pipeline parallelism
- Vision encoder typically 60-70% of total FLOPs
- Scaling behavior: O(n²) with image resolution
2. Encoder → LLM Decoder (Fusion via Cross-Attention)
Pattern: A vision/audio encoder produces tokens; an LLM consumes them via cross-attention (e.g., BLIP-2, Flamingo, LLaVA-style).
Vision Input → Vision Encoder → Visual Tokens
↓
Text Input → Tokenizer → Text Tokens → LLM with Cross-Attention → OutputKey Components:
- Perceiver Resampler: Reduces visual token count for efficiency
- Gated Cross-Attention: Selective information flow between modalities
- Frozen Vision Encoder: Can be shared across requests
- LLM Backbone: Leverages mature language model stacks
Strengths: Strong generative reasoning, leverages mature LLM stacks Systems Note: Vision encoder can be frozen and shared across requests to save FLOPs; LLM KV-cache dominates inference memory
3. Unified Token Models ("One Stack for All")
Pattern: Modality adapters turn pixels/audio/frames into tokens; a single transformer attends over an interleaved stream (text ↔ image ↔ audio).
Vision Input → Vision Encoder → Visual Tokens
Audio Input → Audio Encoder → Audio Tokens } → Unified Transformer → Output
Text Input → Tokenizer → Text TokensArchitectural Innovations:
- Interleaved Training: Mixed vision-language sequence processing
- Adaptive Layer Norms: Modality-specific normalization
- Unified Attention: Single transformer processes all modalities
Strengths: Tight cross-modal reasoning, simpler serving path Systems Note: Image/video tokens explode sequence length; careful token budgeting and efficient attention are mandatory
Visual guide: Transformers, multimodal wiring patterns, and Mixture-of-Experts (MoE)
What role do transformer models and Mixture-of-Experts play in this case?
Short answer: those three "families" are all ways of wiring Transformers together for multimodality. A "Transformer model" (the Vaswani et al. encoder/decoder with self-attention and cross-attention) is the underlying building block; the families differ in how many Transformers you use, how you connect them, and where the cross-modal fusion happens. Mixture-of-Experts (MoE) is an orthogonal scaling technique you can drop into many of these stacks to boost capacity without paying full compute per token.
How the plain Transformer relates
Vanilla Transformer (text-only): self-attention + (optionally) encoder/decoder cross-attention; established in "Attention Is All You Need."
Dual-encoder (contrastive): two Transformer encoders (e.g., ViT for images, a text encoder) mapping to a shared embedding space trained with contrastive loss (CLIP). It's still Transformers, just two encoders trained to align embeddings; no decoder unless you add one later.
Encoder → LLM decoder (fusion via cross-attention): a vision/audio Transformer encoder feeds tokens into a Transformer decoder LLM via cross-attention (Flamingo, BLIP-2, LLaVA). Architecturally this is closest to classic encoder-decoder Transformers, with the "encoder" being the non-text modality and the "decoder" a large language model.
Unified token ("one stack for all"): adapters turn pixels/frames/waveforms into token streams that a single Transformer attends over jointly. It's still one Transformer; the difference is where tokens come from and that sequences can get very long.
So: the three families use Transformers everywhere; they vary by composition and fusion point, not by abandoning Transformers.
Where Mixture-of-Experts fits (and why you might care)
What MoE is: Replace each dense feed-forward (FFN) block inside a Transformer layer with k parallel "experts"; a small router activates only a top-K subset per token. You massively increase parameter count (capacity) but keep FLOPs/token roughly constant. Originally shown by Shazeer et al. (sparsely-gated MoE), made practical at very large scale by GShard and Switch Transformer.
Relevance to multimodal stacks:
-
Capacity where you need it: Multimodal models must cover diverse phenomena (text, OCR, diagrams, video frames, audio). MoE lets the network specialize sub-modules—some experts effectively become better for e.g. OCR-like tokens, others for conversational text, others for temporal/video cues—without running all experts for every token. (This is an empirical pattern; the mechanism is routing, not hard assignment.)
-
Serving trade-offs: Per-token compute is similar to dense (you run only top-K experts), but communication cost appears: each MoE layer typically requires all-to-all traffic across GPUs (expert parallelism). This stresses NVLink/NVSwitch and makes batching/sequence parallel plans more complex; frameworks like GShard were created to make such sharding/routing tractable.
-
Stability & load-balancing: MoE needs routing losses/capacity limits to avoid expert collapse and token dropping; Switch simplifies gating to top-1 (or top-2) to improve stability and throughput.
-
Cost/perf in practice: Recent open MoE LLMs (e.g., Mixtral 8×7B) show that sparse-MoE can beat much larger dense models at similar or lower inference cost by activating only a couple of experts per token. This illustrates the cost-effective capacity argument for MoE in real deployments.
Putting it together (architectural guidance)
Dual-encoder (CLIP-style) + MoE? Useful mainly if you want huge encoders for retrieval while keeping latency reasonable. MoE'd encoders can scale capacity with modest extra compute per image/text, then you index embeddings once. (Generative tasks still need a decoder.)
Encoder→LLM decoder (Flamingo/BLIP-2/LLaVA) + MoE? The hot path at inference is the LLM decoder. Dropping MoE FFNs into the decoder is a common way to get a bigger "brain" for reasoning without linear FLOP growth. Expect engineering for expert-parallel comms and careful batching to keep utilization high.
Unified token models + MoE? These push sequence lengths way up (image/video tokens). MoE can help with capacity, but KV-cache and attention cost still scale with sequence length; MoE doesn't reduce KV size, since experts live in the FFN, not attention. Use MoE plus token-budgeting/pruning and efficient attention. (KV/attention scaling fundamentals per the original Transformer apply here.)
Quick cheat sheet
- "Transformer vs those three?" Not versus—they are all Transformer-based. Differences are in how many Transformers and where you do cross-modal fusion.
- "Where does MoE help?" In the FFN sublayers to add capacity cheaply; most impactful in the LLM decoder of encoder→decoder stacks and in giant retrieval encoders; comes with routing + interconnect engineering costs.
- "What MoE doesn't fix" Long-context memory/latency (attention/KV), or poor data alignment; it's complementary to sequence-length and token-budgeting techniques.
Figure A — Wiring patterns + where MoE fits
- Dual-encoder (contrastive): two Transformer encoders (vision + text) map inputs into a shared embedding space. Trained with a contrastive objective.
- Encoder → LLM decoder: a non-text encoder produces tokens/keys/values that a Transformer decoder LLM consumes via cross-attention.
- Unified token model: one Transformer attends jointly over interleaved tokens from adapters (image/audio/text).
- MoE (blue panel): an FFN → MoE-FFN swap you can apply inside any of the above Transformers. A router activates top-K experts per token, boosting capacity without proportional compute.
Figure B — Why MoE matters for scaling
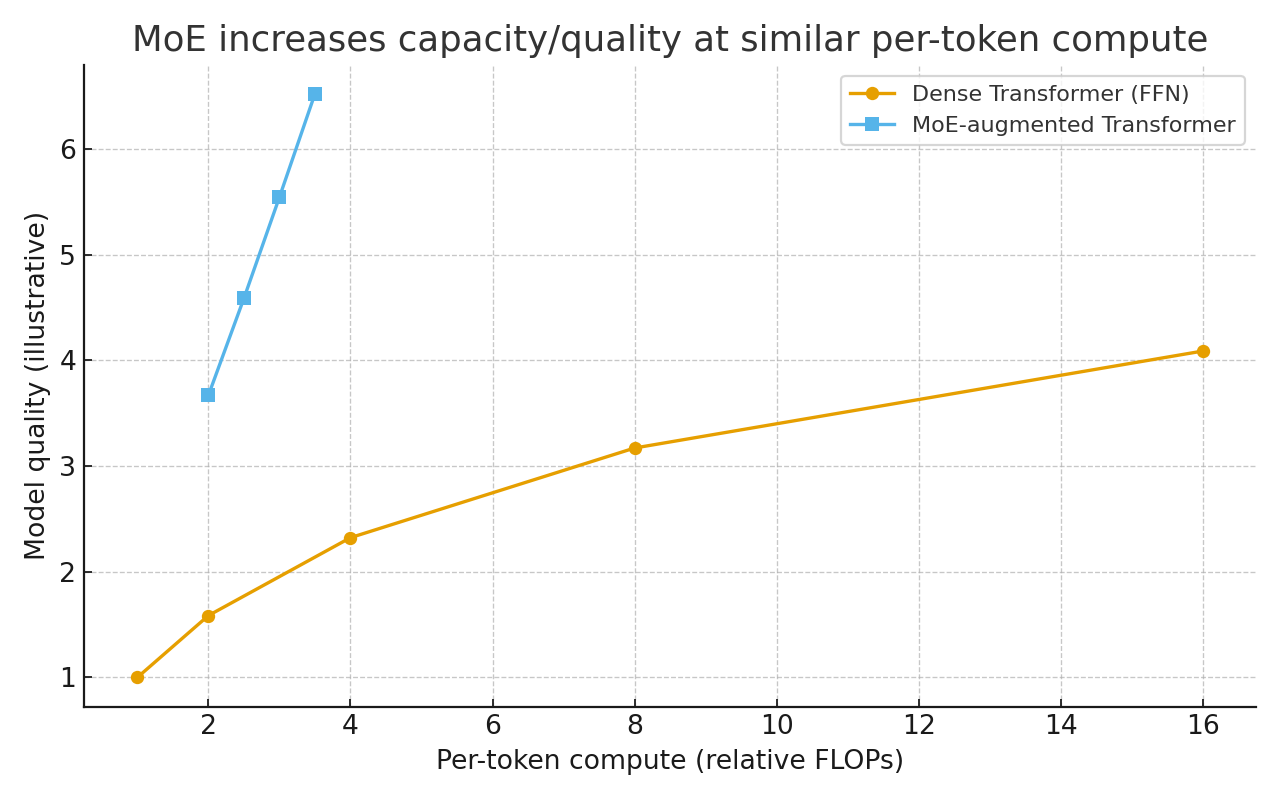 MoE adds parameters (capacity) faster than it adds per-token FLOPs, so you can push quality at similar latency—at the cost of routing and all-to-all communication between devices.
MoE adds parameters (capacity) faster than it adds per-token FLOPs, so you can push quality at similar latency—at the cost of routing and all-to-all communication between devices.
Notes
- These are illustrative diagrams; they capture topology and qualitative trade-offs rather than exact numbers.
⚙️ Cross-Modal Attention Mechanisms
Standard Cross-Attention
The fundamental building block for multimodal interaction:
def cross_modal_attention(query_modal_A, key_value_modal_B):
"""
Q from modality A, K,V from modality B
Enables A to attend to relevant parts of B
"""
attention_weights = softmax(Q @ K.T / sqrt(d_k))
output = attention_weights @ V
return outputComputational Complexity:
- Time: O(n_A × n_B × d) where n_A, n_B are sequence lengths
- Memory: O(n_A × n_B) for attention matrix storage
Efficient Attention Variants
1. Sparse Cross-Attention
- Limits attention to k-nearest neighbors in embedding space
- Reduces complexity from O(n²) to O(n × k)
- Particularly effective for long visual sequences
2. Learned Routing Attention
- Routes queries to relevant key-value pairs using learned policies
- Enables dynamic sparsity patterns
- Critical for handling variable-length multimodal sequences
3. Hierarchical Attention
- Multi-scale attention from coarse to fine features
- Matches natural visual processing patterns
- Reduces computational load while maintaining quality
🔬 Training Methodologies & Signals
Core Training Objectives
1. Contrastive Alignment Pair matching between modalities (text↔image, text↔audio).
InfoNCE Loss for Vision-Language Alignment:
L = -log(exp(sim(v_i, t_i) / τ) / Σ_j exp(sim(v_i, t_j) / τ))Where:
v_i, t_i: Vision and text embeddings for matched pair isim(): Cosine similarity functionτ: Temperature parameter controlling sharpness
2. Generative Objectives Next-token prediction on captions, transcripts, interleaved sequences.
3. Masked/Denoising Masked autoencoding for vision/audio robustness.
4. Instruction & Preference Tuning RLHF/DPO or curated Q&A to follow prompts and reduce hallucinations.
Multi-Task Training Strategies
1. Interleaved Multi-Task Learning
- Randomly sample tasks during training
- Prevents catastrophic forgetting
- Requires careful loss weighting
2. Curriculum Learning
- Progressive difficulty scaling
- Start with simpler vision-language tasks
- Gradually introduce complex reasoning
System Impact:
- Requires large batch sizes (typically 32k+) for effective negatives
- Memory usage scales linearly with batch size
- Benefits from data parallel training across multiple nodes
🎯 What They Can Do (Typical Capabilities)
Core Multimodal Tasks
Image/Video Understanding
- Image captioning and detailed visual descriptions
- Visual Question Answering (VQA) with complex reasoning
- Object detection and visual grounding
- OCR and document understanding
- Chart, table, and plot analysis
- Scene understanding and spatial reasoning
Cross-Modal Retrieval & RAG
- Find the frame that answers a question
- Image-text similarity search
- Video moment retrieval
- Multimodal knowledge base querying
Speech & Audio Tasks
- Automatic Speech Recognition (ASR)
- Speech-to-speech translation
- Audio captioning and sound classification
- Multi-speaker dialogue understanding
Cross-Modal Generation
- Text-to-image generation with fine-grained control
- Image editing from natural language instructions
- Text-to-speech with voice cloning
- Video generation from text descriptions
Agentic & Interactive Use
- Read screenshots and perform UI actions
- Generate code from visual mockups
- Multimodal tool calling and API interaction
- Visual debugging and code explanation
Advanced Reasoning Capabilities
Compositional Understanding
- Multi-hop reasoning across modalities
- Temporal reasoning in video sequences
- Spatial relationship understanding
- Abstract concept grounding
Domain-Specific Applications
- Medical image analysis and diagnosis
- Scientific figure interpretation
- Legal document processing
- Educational content generation
💾 Memory Architecture Considerations
Memory Access Patterns
Cross-Modal Attention Memory Behavior:
Memory_Usage = (seq_len_vision × seq_len_text × batch_size × 4_bytes)
+ (model_parameters × 4_bytes) // FP32 weights
+ (activations_cache × layers)For Typical Models:
- CLIP ViT-Large: ~300M parameters, 16GB peak memory (batch=32)
- DALL-E 2: ~3.5B parameters, 48GB peak memory during generation
- Flamingo-80B: ~80B parameters, 160GB+ memory for inference
Memory Optimization Strategies
1. Gradient Checkpointing
- Trade compute for memory by recomputing activations
- Particularly effective for attention layers
- Can reduce memory usage by 50-80%
2. Mixed Precision Training
- FP16/BF16 for forward/backward passes
- FP32 for parameter updates
- Requires careful gradient scaling
3. Parameter Sharing
- Share weights between modality encoders where possible
- Reduces parameter count while maintaining capability
- Effective for similar architectural components
🚀 System Architecture for Deployment
Inference Pipeline Design
Synchronous Processing Pipeline:
Input Processing → Multimodal Encoding → Cross-Modal Fusion → Generation
↓ ↓ ↓ ↓
Image/Text Vision/Text Emb. Unified Repr. Output Tokens
Parallel Parallel Sequential SequentialAsynchronous Processing for Scale:
class MultimodalInferenceServer:
def __init__(self):
self.vision_encoder = VisionEncoder() # GPU 0-1
self.text_encoder = TextEncoder() # GPU 2
self.fusion_model = FusionModel() # GPU 3-4
async def process_request(self, image, text):
# Parallel encoding
vision_task = self.vision_encoder.encode_async(image)
text_task = self.text_encoder.encode_async(text)
# Wait for both encoders
vision_emb, text_emb = await asyncio.gather(vision_task, text_task)
# Sequential fusion and generation
return await self.fusion_model.generate(vision_emb, text_emb)Hardware Optimization Strategies
1. Heterogeneous Computing
- Vision processing: High-memory GPUs (A100, H100)
- Text processing: Lower-memory, high-compute GPUs
- Preprocessing: CPU with vector instructions
2. Model Partitioning
- Split large models across multiple devices
- Minimize cross-device communication
- Pipeline parallelism for sequential components
3. Caching Strategies
- Cache vision encodings for repeated images
- Implement KV-cache for autoregressive generation
- Use semantic caching for similar prompts
⚙️ Practical Systems & Microarchitectural Implications
Token Budgeting & Sequence Length Management
The Core Challenge: Vision tokens (e.g., 14×14 ViT patches) and especially video (T×H×W) explode sequence length and KV memory.
Key Implications:
- KV Cache Growth: Expect KV cache ≫ parameters at inference
- Memory Scaling: KV memory grows linearly with sequence length (see Figure 2)
- Attention Complexity: Quadratic scaling with combined text+vision sequence length
Mitigation Strategies:
- Token Pruning: Remove redundant visual tokens based on attention weights
- Pooling & Compression: Adaptive pooling for less critical image regions
- Image Prefix Compression: Compress repeated visual context
- Block-Sparse Attention: Limit attention patterns for long sequences
KV Cache & Memory Management
Memory Breakdown:
Memory_Usage = (seq_len_vision × seq_len_text × batch_size × 4_bytes) // KV cache
+ (model_parameters × 4_bytes) // FP32 weights
+ (activations_cache × layers) // Forward passOptimization Techniques:
- Key/Value Quantization: INT8/INT4 KV cache (can halve memory vs FP16)
- Sliding Window: For streaming audio/video applications
- Gradient Checkpointing: Trade compute for memory during training
- KV Cache Streaming: Partial cache eviction for long sequences
Throughput vs. Latency Trade-offs
Compute Balance Considerations:
- Vision Encoders: Dense GEMMs, compute-bound
- LLM Decode: Memory/latency-bound, bandwidth-limited
- Prefill vs. Decode: Prefill has high arithmetic intensity; decode is KV-cache limited
- Multimodal Penalty: Extra context tokens inflate decode cost
Optimization Strategies:
- Precompute/Freeze: Vision/audio embeddings when possible; share across batch
- Heterogeneous Hardware: High-memory GPUs for vision, compute-optimized for text
- Pipeline Parallelism: Split encoders and decoders across devices
Data Pipeline & I/O Bottlenecks
Common Bottlenecks:
- JPEG/MP4 Decode: Can starve accelerators at high throughput
- Data Augmentation: CPU preprocessing becomes limiting factor
- Storage Bandwidth: Large image/video datasets stress I/O subsystem
Solutions:
- Pin CPU Decode: Dedicated CPU cores for media processing
- Fused GPU Transforms: Move augmentation to GPU when possible
- Embedding Caching: Cache encodings for frequently accessed media
- Async I/O: Overlap data loading with computation
Scheduling & Batching Strategies
Challenge: Interleaved text–image prompts break uniform batching assumptions.
Advanced Techniques:
- Continuous/Rolling Batching: Sustain higher tokens/sec at scale (see Figure 3)
- Request Bucketing: Group by token budget and modality mix
- Dynamic Batching: Adjust batch size based on sequence length distribution
- Priority Scheduling: Latency-sensitive requests get preferential treatment
📊 Performance Optimization
Compute-Bound Optimizations
1. Kernel Fusion
- Fuse attention operations with subsequent linear layers
- Reduce memory bandwidth requirements
- Particularly effective for cross-attention
2. Flash Attention for Cross-Modal Attention
def flash_cross_attention(Q, K, V, block_size=64):
"""
Memory-efficient cross-attention using tiling
Reduces memory from O(n²) to O(n)
"""
# Implementation details involve careful tiling
# to maximize GPU utilization while minimizing memory3. Mixed Expert Models
- Route different modalities to specialized experts
- Activate subset of parameters per input
- Maintains capacity while reducing computation
Memory-Bound Optimizations
1. Quantization
- INT8 quantization for deployment
- Careful handling of attention operations
- Calibration on representative multimodal data
2. Pruning Strategies
- Structured pruning of attention heads
- Remove redundant cross-modal connections
- Magnitude-based parameter pruning
3. Knowledge Distillation
- Train smaller student models
- Maintain multimodal capabilities
- Reduce inference cost by 5-10x
🔍 Evaluation Metrics & Benchmarks
Capability Assessment
1. Cross-Modal Retrieval
- Image-to-text and text-to-image retrieval accuracy
- Measures alignment quality
- Standard benchmarks: Flickr30k, MS-COCO
2. Visual Question Answering
- Complex reasoning across modalities
- Benchmarks: VQAv2, GQA, OK-VQA
- Tests compositional understanding
3. Multimodal Generation Quality
- FID scores for image generation
- CLIP scores for text-image alignment
- Human evaluation for complex tasks
System Performance Metrics
1. Latency Characteristics
- End-to-end inference latency
- Breakdown by model component
- Scaling with input complexity
2. Throughput Analysis
- Requests per second under load
- Memory usage patterns
- GPU utilization efficiency
3. Resource Efficiency
- Compute per token generated
- Memory per concurrent request
- Power consumption analysis
🎯 Real-World Applications
Multimodal Chatbots
System Requirements:
- Low latency for interactive use (sub-2s response)
- High throughput for concurrent users
- Robust handling of diverse input types
Architecture Considerations:
class MultimodalChatBot:
def __init__(self):
self.vision_cache = LRUCache(maxsize=1000) # Cache encodings
self.model = MultimodalModel()
self.context_manager = ContextManager()
def process_message(self, text, image=None, context_id=None):
# Retrieve conversation context
context = self.context_manager.get_context(context_id)
# Process inputs with caching
if image:
vision_emb = self.vision_cache.get(image_hash(image))
if not vision_emb:
vision_emb = self.model.encode_vision(image)
self.vision_cache[image_hash(image)] = vision_emb
# Generate response
return self.model.generate(text, vision_emb, context)Content Generation Systems
Challenges:
- High memory requirements for generation
- Quality consistency across modalities
- Scalable serving infrastructure
Solutions:
- Staged generation pipelines
- Quality filtering mechanisms
- Distributed serving architectures
Autonomous Systems
Real-Time Constraints:
- Sub-100ms latency for safety-critical decisions
- Continuous processing of sensor streams
- Robust failure handling
System Design:
- Edge deployment with model compression
- Hierarchical processing (fast→detailed)
- Fallback mechanisms for edge cases
📊 Evaluation & Limitations
Benchmark Landscape
Cross-Modal Understanding
- OCR Tasks: DocVQA, TextVQA for document understanding
- Chart/Table QA: ChartQA, TabFact for structured visual data
- Science Diagrams: AI2D, ScienceQA for technical figure reasoning
- Video Understanding: Video-QA, ActivityNet for temporal reasoning
Speech & Audio
- Speech Recognition: WER (Word Error Rate) on diverse accents/domains
- Translation: BLEU scores for speech-to-speech translation
- Audio Classification: Environmental sound recognition benchmarks
Grounded Generation
- Text-to-Image: FID scores, CLIP scores for semantic alignment
- Image Editing: Faithfulness to instructions, preservation of unmodified regions
- Factual Accuracy: Grounded captioning with verification against knowledge bases
Common Failure Modes & Limitations
Visual Misgrounding
- Difficulty with spatial relationships ("left" vs "right")
- Small text OCR in complex documents
- Fine-grained object distinctions in cluttered scenes
Language Bias & Hallucination
- Over-reliance on language priors when visual information is ambiguous
- Generating plausible but incorrect details not present in the image
- Cultural and demographic biases in training data
Temporal & Sequential Reasoning
- Challenges with long video sequences
- Understanding cause-and-effect relationships across frames
- Maintaining consistency in multi-turn conversations with visual context
Domain Shift Sensitivity
- Performance degradation on specialized domains (medical, industrial, scientific)
- Difficulty with low-resource languages or specialized vocabularies
- Sensitivity to image quality, lighting, and perspective changes
Scale & Resource Requirements
- Computational demands limit accessibility for smaller organizations
- Long context handling remains challenging for resource-constrained deployments
- Fine-tuning requires significant domain-specific data and compute
Visual Summary
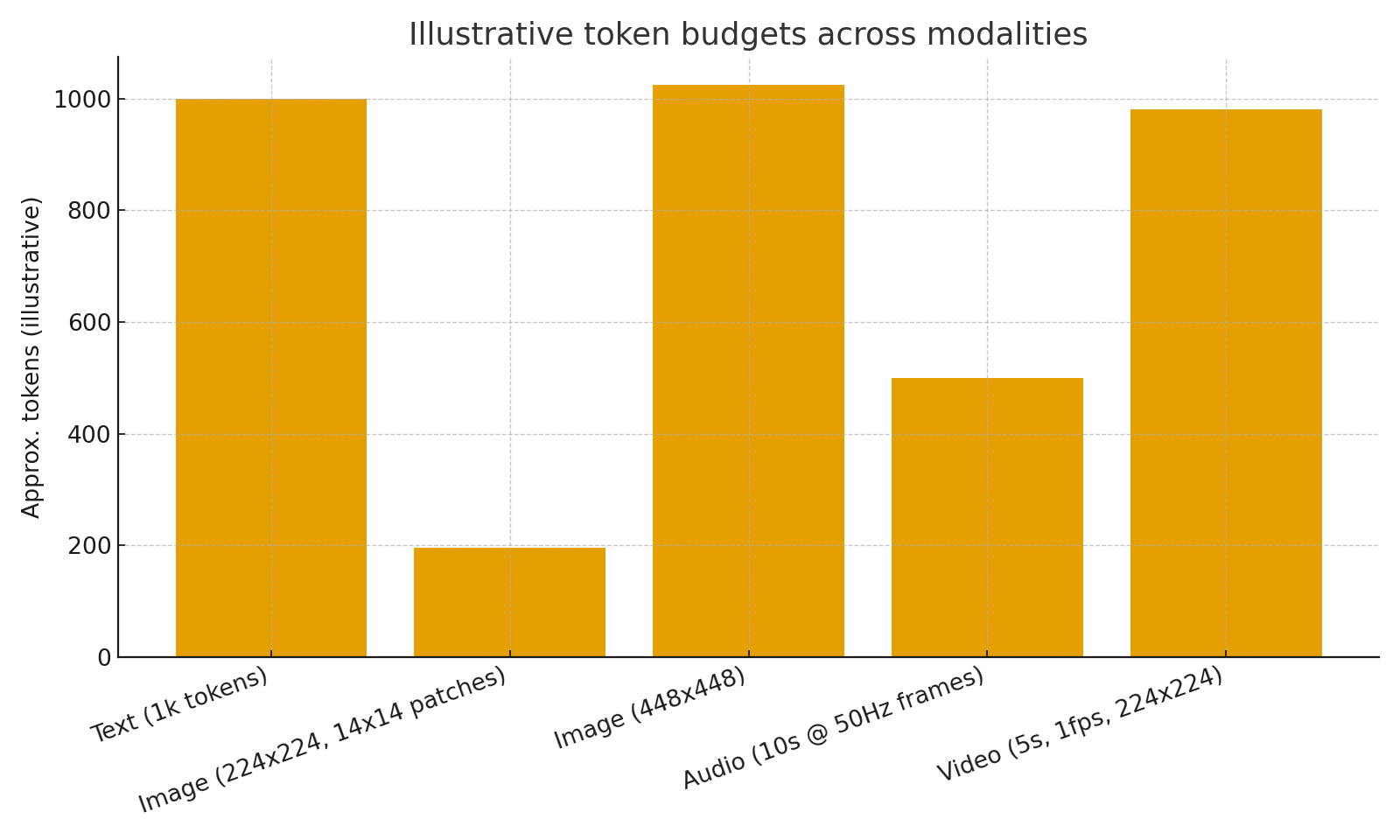 Figure 1. Token pressure grows quickly for images and especially video; careful token budgeting is essential.
Figure 1. Token pressure grows quickly for images and especially video; careful token budgeting is essential.
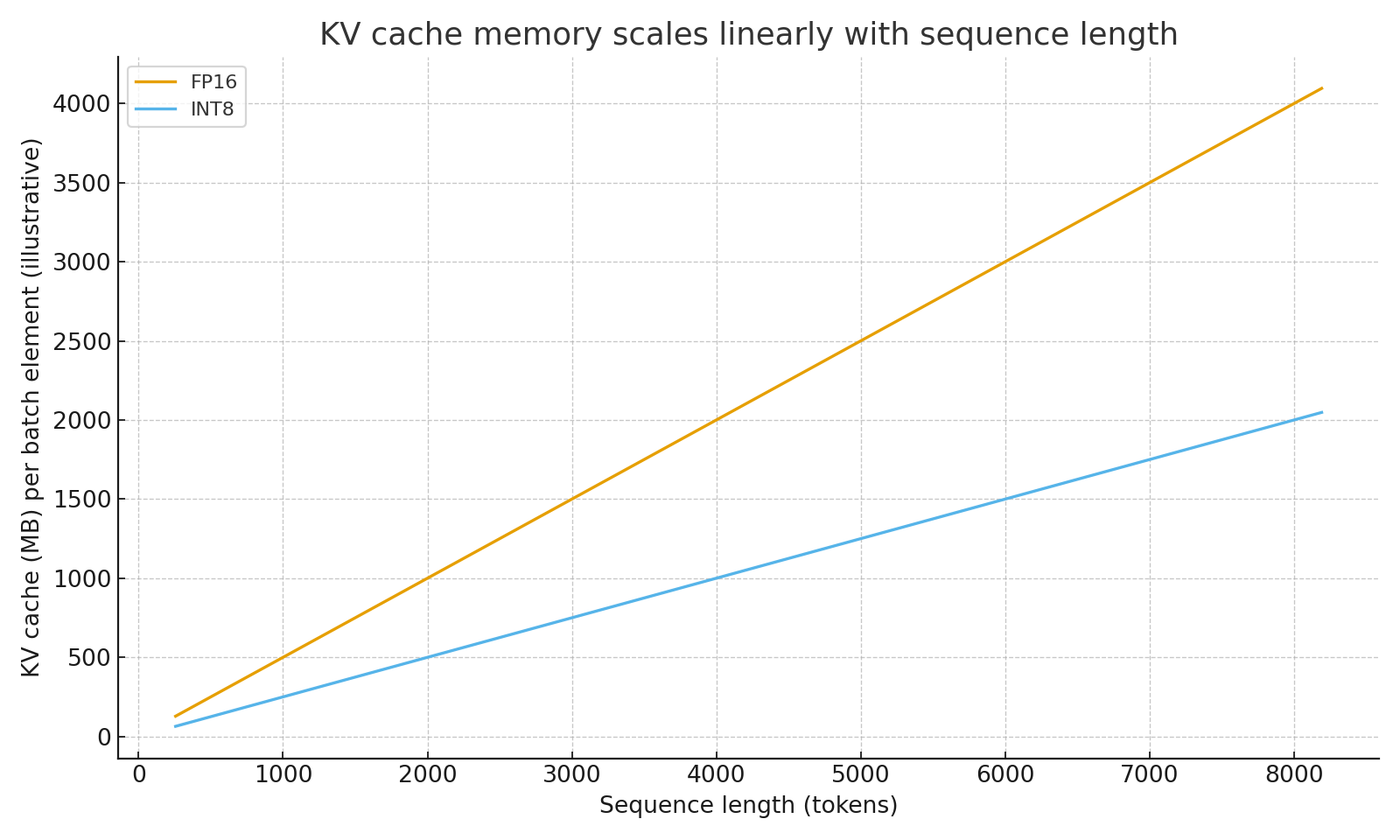 Figure 2. KV cache memory grows linearly with sequence length; INT8 KV can halve memory vs FP16.
Figure 2. KV cache memory grows linearly with sequence length; INT8 KV can halve memory vs FP16.
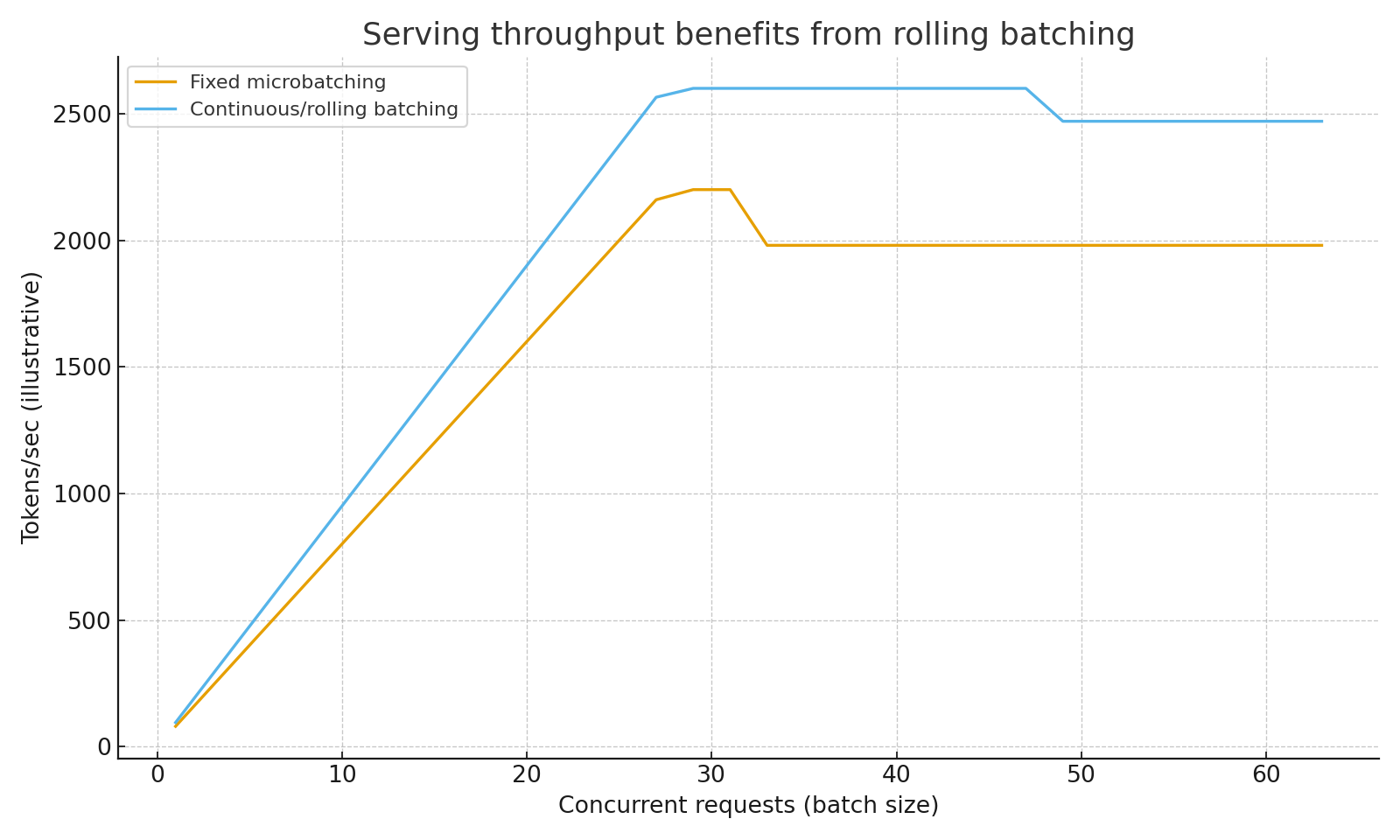 Figure 3. Rolling/continuous batching sustains higher tokens/sec at larger concurrency.
Figure 3. Rolling/continuous batching sustains higher tokens/sec at larger concurrency.
🎯 When to Use Multimodal Foundation Models
Ideal Use Cases
Choose multimodal models when your task inherently mixes modalities:
Document & Content Understanding
- Documents with figures, charts, and tables
- Technical manuals with diagrams
- Legal documents with visual evidence
- Scientific papers with experimental figures
Interactive & Agentic Applications
- UI automation from screenshots
- Visual debugging and code generation
- Multi-step reasoning with visual feedback
- Educational tutoring with visual aids
Creative & Generative Tasks
- Content creation mixing text and visuals
- Image editing with natural language
- Video analysis and summarization
- Cross-modal style transfer
Real-Time & Streaming Applications
- Meeting transcription with slide analysis
- Live video Q&A and commentary
- Industrial inspection with natural language reporting
- Medical diagnosis with multimodal patient data
When to Avoid
Consider alternatives for:
Text-Only Workloads
- Pure language understanding tasks
- Text generation without visual context
- Traditional NLP applications (sentiment, classification)
Latency-Critical Edge Applications
- Real-time embedded systems with strict SLA requirements
- Battery-constrained mobile applications
- High-frequency trading or control systems
Simple Single-Modal Tasks
- Basic image classification or object detection
- Standard speech recognition without visual context
- Document processing with consistent formatting
Resource-Constrained Environments
- Applications requiring sub-second inference on CPU
- Scenarios where model size must be under 1GB
- Deployments without GPU acceleration
Decision Framework
Evaluate along these dimensions:
- Modality Integration: Does the task require understanding across modalities?
- Resource Budget: Can you afford the computational and memory overhead?
- Latency Requirements: Are sub-second responses critical?
- Data Availability: Do you have sufficient multimodal training data?
- Accuracy vs. Cost: Does the multimodal capability justify the increased complexity?
📁 Data Considerations
Alignment Quality & Sources
High-Quality Pairs Drive Performance
- Web Alt-Text: Abundant but noisy, often generic or inaccurate
- Synthetic Captions: Cleaner but can import language model biases
- Ground-Truth Annotations: Medical images, technical documents, chart-QA datasets
- Curated Datasets: Human-verified image-text pairs for critical domains
Data Quality Impact
- Alignment quality matters more than quantity for cross-modal understanding
- Noisy web data can lead to persistent hallucination patterns
- High-signal pairs (technical documentation, scientific figures) drive major capability gains
Licensing & Privacy Compliance
Legal Considerations
- Image Rights: Web-scraped images may have copyright restrictions
- Voice Data: Speech samples often contain PII and require consent
- Video Content: Complex licensing for educational, entertainment, and news content
- Medical Data: HIPAA compliance for healthcare applications
Privacy & Redaction Pipelines
- PII Detection: Automated detection of faces, personal information in images
- Voice Anonymization: Speaker identity removal while preserving linguistic content
- Consent Management: Tracking and honoring data subject requests
- Audit Trails: Maintaining records of data usage and transformations
Implementation Requirements
- Compliance and redaction pipelines are table stakes for production deployment
- Regular audits of training data sources and usage rights
- Geographic restrictions and data localization requirements
- Integration with enterprise data governance frameworks
⚠️ Common Pitfalls & Solutions
Training Instabilities
Problem: Cross-modal alignment can be unstable during early training Solution:
- Warm-up schedules for cross-attention layers
- Careful initialization of fusion components
- Progressive unfreezing of model components
Memory Management
Problem: Attention memory grows quadratically with sequence length Solutions:
- Implement gradient checkpointing
- Use efficient attention variants (Flash, Ring)
- Careful batch size tuning
Evaluation Challenges
Problem: Limited benchmarks for novel capabilities Solutions:
- Design application-specific evaluations
- Human evaluation protocols
- Adversarial testing for robustness
🔮 Future Directions
Architectural Innovations
1. Unified Multimodal Transformers
- Single architecture handling all modalities
- Learned modality-specific tokenization
- Dynamic routing based on input type
2. Retrieval-Augmented Multimodal Models
- External knowledge integration
- Real-time information updates
- Scalable memory mechanisms
3. Efficient Training Methods
- Few-shot multimodal learning
- Continual learning without forgetting
- Meta-learning for new modality pairs
System-Level Advances
1. Specialized Hardware
- Multimodal accelerators
- On-chip memory optimization
- Cross-modal processing units
2. Distributed Architectures
- Edge-cloud hybrid systems
- Federated multimodal learning
- Privacy-preserving multimodal AI
📚 Essential Reading
Foundational Papers
- CLIP: "Learning Transferable Visual Representations from Natural Language Supervision" (OpenAI, 2021)
- DALL-E: "Zero-Shot Text-to-Image Generation" (OpenAI, 2021)
- Flamingo: "Tackling the Visual Question Answering Challenge" (DeepMind, 2022)
- GPT-4V: "GPT-4V(ision) System Card" (OpenAI, 2023)
System Architecture
- Efficient Transformers: "A Survey of Efficient Transformers" (Tay et al., 2020)
- Flash Attention: "FlashAttention: Fast and Memory-Efficient Exact Attention" (Dao et al., 2022)
- Model Parallelism: "Megatron-LM: Training Multi-Billion Parameter Language Models" (Shoeybi et al., 2019)
Recent Advances
- Multimodal Reasoning: "Visual Instruction Tuning" (Liu et al., 2023)
- Efficient Multimodal: "LLaVA: Large Language and Vision Assistant" (Liu et al., 2023)
- System Optimization: "PaLM-E: An Embodied Multimodal Language Model" (Driess et al., 2023)
Key Takeaways
🎯 For System Architects:
- Multimodal models require careful memory hierarchy design
- Cross-attention creates unique computational patterns
- Serving requires specialized pipeline architectures
⚡ For Performance Engineers:
- Attention operations dominate memory bandwidth
- Model partitioning is critical for large models
- Caching strategies dramatically improve efficiency
🏗️ For Infrastructure Teams:
- Heterogeneous hardware deployments are often optimal
- Batch size tuning is critical for throughput
- Monitoring requires multimodal-specific metrics
Next Module: Continue to MLPerf Benchmarks & Workload Analysis to learn how to evaluate and optimize multimodal systems using standardized benchmarks.