Transformer Architecture: Compute & Data Movement Characteristics
Understanding the phases of transformer architecture and their NoC traffic patterns, from embedding to self-attention to feedforward layers.
Prerequisites
Make sure you're familiar with these concepts before diving in:
Learning Objectives
By the end of this topic, you will be able to:
Table of Contents
98% of this content was generated by LLM.
Table of Contents
- 🚀 Phases of Transformer Architecture in Terms of Computation & Data Movement
🚀 Phases of Transformer Architecture in Terms of Computation & Data Movement
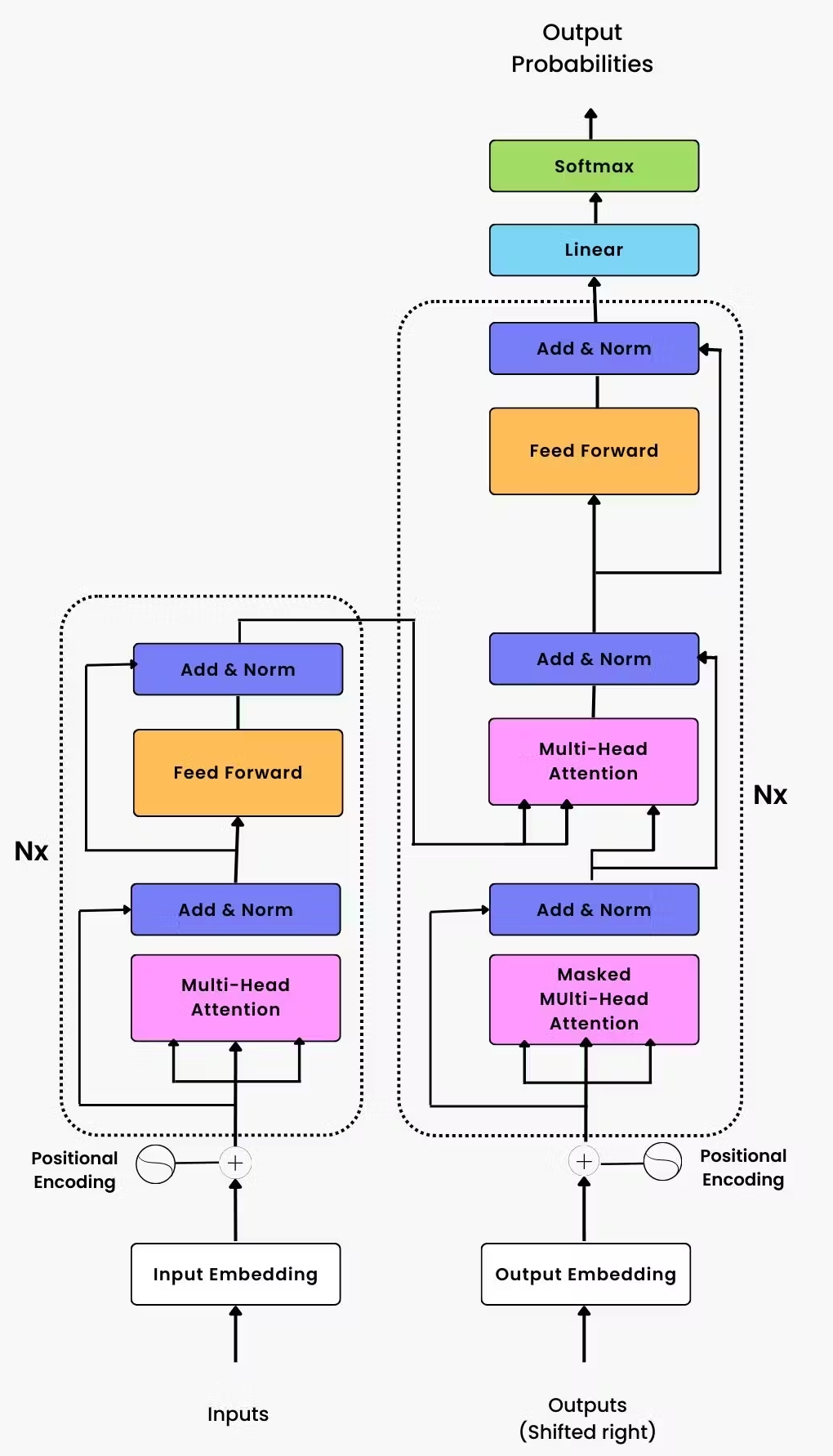
The Transformer model (used in GPT, BERT, LLaMA, etc.) consists of multiple stages of computation, each with unique NoC (Network-on-Chip) stress patterns. Understanding these phases is crucial for optimizing AI accelerators.
📌 1. High-Level Phases of Transformer Computation
The Transformer model operates in three major phases during training and inference:
| Phase | Computation Type | Data Movement Characteristics | Latency Bottlenecks |
|---|---|---|---|
| 1. Embedding & Input Projection | Lookup tables, matrix multiplications | Reads from memory, low bandwidth | Memory access time |
| 2. Multi-Head Self-Attention (MHSA) | Matrix multiplications (QKV), softmax | High bandwidth, many-to-many communication | NoC congestion |
| 3. Feedforward Layers (MLP) | Fully connected layers (FC), activation functions | Less bandwidth, structured memory access | Memory latency |
| 4. Layer Norm & Residual Connections | Element-wise operations, normalization | Small memory access, low NoC traffic | Minimal latency impact |
| 5. Output Projection & Softmax | Softmax, final probability computation | Heavy memory writes | Last-layer memory bottleneck |
🚀 Key Takeaway:
- MHSA phase is the most NoC-intensive part due to massive all-to-all communication.
- Feedforward (MLP) layers are compute-heavy but require structured memory access.
📚 References
For deeper understanding of Transformer architecture and visualization:
- The Illustrated Transformer by Jay Alammar - An excellent visual guide to understanding the Transformer architecture with step-by-step illustrations
- Transformer Explainer - An interactive visualization tool that lets you explore how Transformers work at multiple levels of abstraction
📌 2. Step-by-Step Transformer Data Flow
🚀 Phase 1: Embedding & Input Projection
🔹 Computation: Convert input tokens into dense vector embeddings. Perform matrix multiplications to project embeddings into the model's hidden space.
🔹 Data Movement in NoC:
| Operation | NoC Traffic Type |
|---|---|
| Read embeddings from memory | Memory-to-core transfer (HBM) |
| Compute input projections | Local core communication |
| Store projected embeddings | Write to DRAM/HBM |
✅ NoC Behavior: Low traffic → Mostly memory-bound, not NoC-intensive. Bottleneck: DRAM bandwidth if embeddings are large.
🚀 Phase 2: Multi-Head Self-Attention (MHSA)
📌 Most NoC-Intensive Phase!
🔹 Computation:
- Compute Query (Q), Key (K), and Value (V) matrices.
- Perform QK^T (Attention Score Calculation).
- Apply Softmax & Weighted Sum of Values.
🔹 Data Movement in NoC:
| Operation | NoC Traffic Type |
|---|---|
| Broadcast Key (K) and Value (V) to all heads | All-to-All (many-to-many) |
| Compute QK^T | Memory-intensive tensor multiplication |
| Softmax normalization | Local core memory accesses |
| Weighted sum of values | High-bandwidth data movement |
✅ NoC Behavior:
Extreme congestion → NoC must support high-bandwidth many-to-many traffic.
Major bottleneck → Memory-bound attention operations slow down inference.
Optimization needed → Hierarchical interconnects (NVLink, Infinity Fabric) reduce contention.
🚀 Phase 3: Feedforward Layers (MLP)
📌 Compute-Intensive Phase
🔹 Computation:
- Linear transformation via fully connected (FC) layers.
- Non-linear activation functions (ReLU, GeLU, SiLU).
🔹 Data Movement in NoC:
| Operation | NoC Traffic Type |
|---|---|
| FC layer computation | Core-local memory access |
| Activation function (ReLU, GeLU) | Minimal memory movement |
| Store intermediate results | Write to HBM (if batch size is large) |
✅ NoC Behavior:
Structured memory access → Less NoC congestion than attention. Compute-bound bottleneck → Optimized tensor cores help accelerate FC layers.
🚀 Phase 4: Layer Norm & Residual Connections
📌 Lightweight Memory Operations
🔹 Computation:
- Normalize activation outputs (LayerNorm).
- Add residual connection (skip connection).
🔹 Data Movement in NoC:
| Operation | NoC Traffic Type |
|---|---|
| Read intermediate activations | Memory-to-core transfer |
| Apply element-wise LayerNorm | Minimal NoC load |
| Perform residual sum | Low-bandwidth local computation |
✅ NoC Behavior:
Low NoC stress → No global communication required. Minimal bottlenecks → Mostly memory latency bound.
🚀 Phase 5: Output Projection & Softmax
📌 Final Memory-Intensive Step
🔹 Computation: Compute final token probabilities using softmax. Select the next token during inference.
🔹 Data Movement in NoC:
| Operation | NoC Traffic Type |
|---|---|
| Compute output probabilities | High memory bandwidth needed |
| Store results for next token | Memory write operation |
✅ NoC Behavior:
Latency bottleneck in last layer → Softmax reads large activation data. Memory bandwidth limited → If batch size is large, DRAM access slows down processing.
📌 3. How NoC Behavior Changes Over Time
The NoC traffic pattern changes dynamically across transformer layers.
✅ Transformer NoC Traffic Over Time
| Phase | Traffic Pattern | Bottleneck |
|---|---|---|
| Embedding | Low traffic (read-heavy) | Memory latency |
| MHSA (Self-Attention) | All-to-all NoC congestion | Memory bandwidth & communication delays |
| MLP (Feedforward Layers) | Compute-heavy, structured NoC usage | Compute efficiency |
| LayerNorm & Residual | Minimal NoC traffic | None |
| Output Projection | Memory writes, softmax communication | DRAM bandwidth |
📌 Observations:
Early phases (Embedding, Attention) are memory-bound. MHSA creates the most NoC congestion (all-to-all traffic). MLP (Feedforward) is compute-heavy, but NoC load is lower.
📌 4. NoC Optimizations for Transformer Models
Since MHSA creates the most NoC congestion, AI accelerators optimize their interconnects:
✅ Techniques to Optimize NoC for Transformer Workloads
| Optimization | Benefit |
|---|---|
| Hierarchical Interconnects (NVLink, Infinity Fabric) | Reduces NoC congestion by distributing traffic. |
| 3D NoC Architectures | Reduces average hop count and improves bandwidth. |
| Express Virtual Channels (EVCs) | Allows priority paths for critical tensor transfers. |
| Sparse Attention Techniques | Reduces the total number of all-to-all memory accesses. |
📌 5. Final Takeaways
✅ Self-Attention (MHSA) is the biggest NoC bottleneck due to all-to-all communication. ✅ MLP layers stress compute but not NoC as much (mostly structured memory accesses).